머신 러닝 ch3) 모델 정확도 평가 (Assessing Model Accuracy)
Assessing Model Accuracy
- 기계학습 알고리즘은 매우 많음 -> 하지만 모든 데이터에 가장 잘 맞는 단일한 방법은 없음
- 핵심 질문 : 어떤 학습 방법이 더 좋은 결과를 낼까?
-> 즉, 다양한 방법을 어떻게 비교할 수 있을까?
how to compare different learning methods?
Measuring quality of fit (정확도 측정)
For regression problem,

=> 예측값 y^와 실제값 y 사이의 제곱 오차의 평균
=> MSE가 작을수록 더 좋은 모델
Training MSE vs Test MSE
- training MSE : easy to minimize
- but, training MSE != test MSE
- test MSE is what we really want to minimize (테스트 MST를 줄이는 것이 목적!!)
-> 학습 데이터에만 과하게 맞춘 모델은 테스트 데이터에서는 성능이 떨어질 수 있음 (Overfitting)

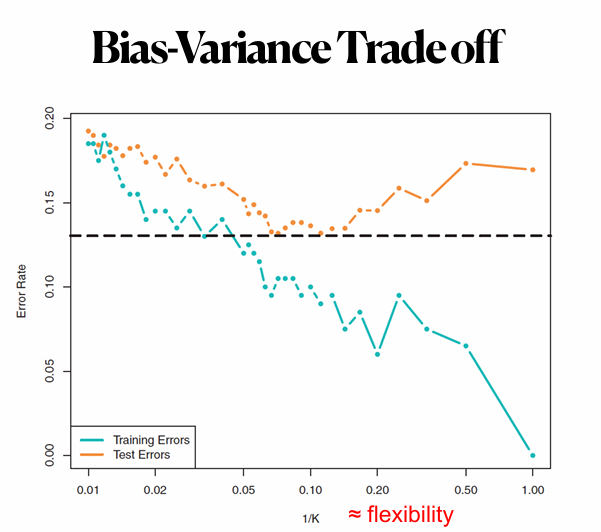
-> 점점 유연한 모델이 될수록 학습 오차는 줄어들지만, 테스트 오차는 U자 형태로 바뀜
-> 너무 유연한 모델은 훈련 데이터에 너무 집착해서 일반화 성능이 떨어짐
-> 훈련 MSE는 작지만, 테스트 MSE는 커질 수 있음

-------------------------------------------------------------------------------------------------------------------------
Why do we see the U-shape in the test MSE ?
(Bias-Variance Trade-Off)

Bias = gap between the real problem and our model
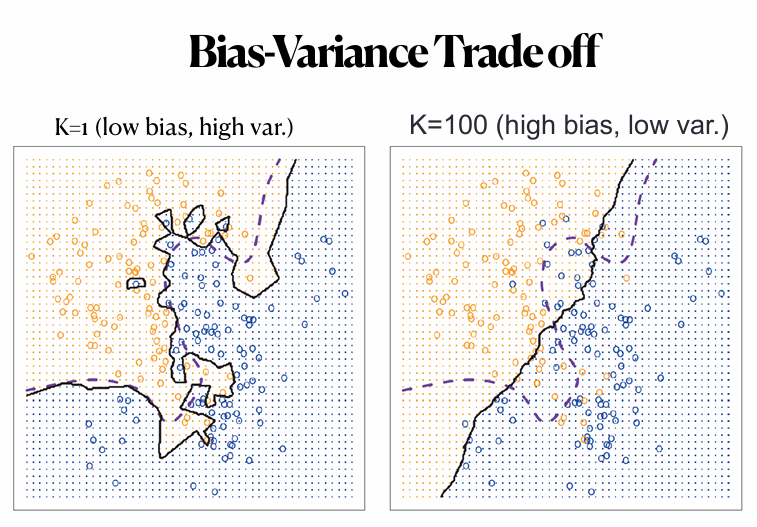
- more flexible model -> lower bias
Variance = change for different training data sets
- more flexible model -> higher variance
=> more flexible model => variance will increase and the bias will decrease
(Cannot decrease variance and bias simultaneously!)



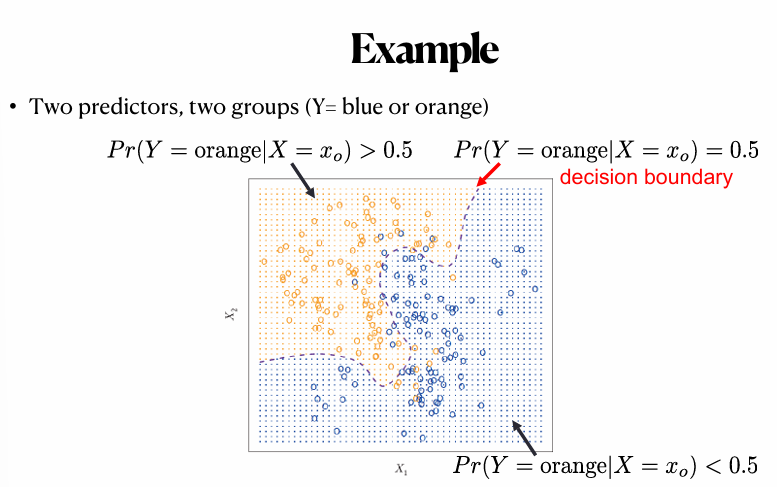
Classification setting
- In a classification problem, y is categorical
- So, we use the error rate(오차율) as a measure
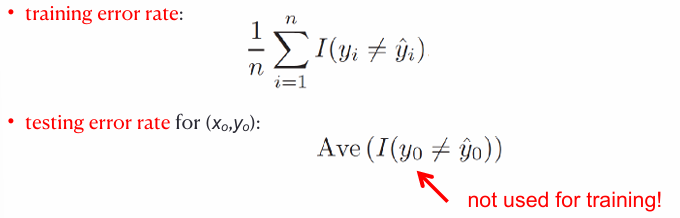
-> trade-off between bias and variance
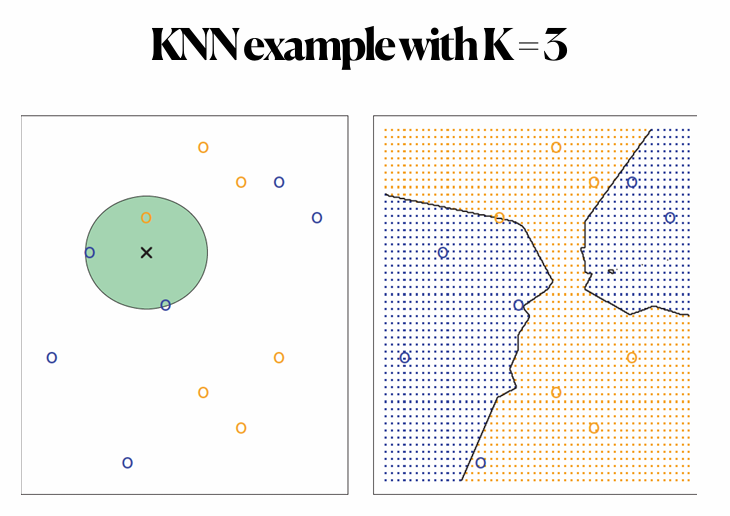
K-nearset neighbors classifier
- 새로운 관측치 x0에 대해 가장 가까운 K개 이웃을 찾아서 다수결로 예측
(Given x0, find the K closest neighbors to x0 in the training data)
- K가 작을수록 낮은 편향, 높은 분산
- K가 클수록 높은 편향, 낮은 분산