분산분석 - ANOVA
정규분포하는지 Check
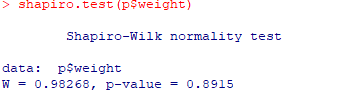
- shapiro.test(p$weight)
bartlett.test(weight~group, data=p)

aov(weight~group, data=p)

summary로 확인
-> Pr <0.05이기 때문에 그룹끼리의 평균은 다르다는 것을 알 수 있다.
(BUT, 어떤 그룹끼리가 다른지는 확인할 수가 없다.)

어떤 그룹끼리의 평균이 다른지를 Check 하는법
-> 그래프에서 0.0을 포함하지 않는 것이 다른것!!!!!!!!!!!
-> or 맨 오른쪽 p adj < 0.05 인 것이 다른것!!!!!!!

참고
https://kilhwan.github.io/bizstat-book/ch-anova.html
Chapter 13 분산 분석 | R을 이용한 통계 분석 (개정판)
경영통계분석실습의 교재를 위해 제작되었습니다.
kilhwan.github.io
https://statisticsplaybook.com/if-else-and-case-when-in-r/
가장 중요한 R 조건문 2가지! if와 case_when | Statistics Playbook
데이터 분석에서 조건 기반 처리는 필수적인 작업입니다. R에서는 이를 위한 다양한 구문들을 제공하는데, 특히 if 함수와 dplyr 패키지의 case_when 함수가 가장 기본적이고 중요합니다. 이 글에서
statisticsplaybook.com
시험 문제
- 참고문서에서 필요한 데이터 추출
-BP1을 B로 변환(범주형 자료를 수치형 자료로 변환하는 과정임)
| BPI | B |
| 1 | 4 |
| 2 | 3 |
| 3 | 2 |
| 4 | 1 |
| 8 | 없음 |
| 9 | 없음 |
b1 = b%>%select(sex, age, HE_BMI, BP1)
b2 = b1[b1$BP1<=4, ] // BP1==8,9값을 제외한 값 불러오기
b3 = na.omit(b2) // 결측치 제거
if ~ when 구문 사용하여 BP1을 B로 변환
-카테고리컬 변수를 1,2,3과 같은 형식의 그룹으로 나누면 (1,2,3을 카테고리가 아니라 수치형 자료로 인식함)
-분산 분석을 할 때 out = aov(weight~factor(gr), data=p)로 해야함 (factor을 추가!!)

영향을 주는 변수는 x ( 경제활동 유무 )
영향을 받는 변수는 y ( 평균 수면 시간 )
qqnorm(p$y)
qqline(p$y)
var.test(y~x, data=p)
'데이터 분석 및 실습' 카테고리의 다른 글
| 데이터 분석 및 실습 10주차 (Chi-square test) (0) | 2024.11.06 |
|---|---|
| 데이터 분석 및 실습 10주차 (다중회귀분석) (1) | 2024.11.04 |
| 데이터 분석 및 실습 9주차 (다중회귀분석) (1) | 2024.10.30 |
| 데이터 분석 및 실습 9주차(상관분석, 회귀분석) (0) | 2024.10.28 |
| 데이터 분석 및 실습 6주차 (T 검정) (0) | 2024.10.07 |