Evolution of Storage Medium

Flash Memory의 위치

NOR : 캐시 메모리처럼 작고 속도는 엄청 빠름(고가)
NAND : 범용 데이터를 저장(문서, 동영상 등), NOR에 비해 저가
가격 비교

-> HDD 와 SDD의 가격 차이가 점점 줄어들고 있음
플래시 메모리를 쓰는 이유
1. 빠른 접근 속도 (데이터를 읽고/쓰기 위해서, 하드 디스크보다 평균적으로 빠르다)
-> 덮어쓰기 등 과정에서 느릴 가능성도 있음
2. 작은 전력 소비량
(하드 디스크는 기계적인 장치로 구성되어 있기 때문에 전력 소비량이 크다)
(플래시 메모리는 기계적인 장치가 없음)
3. 내구성
4. 작은 크기
5. 작은 무게
6. 소리가 안 남

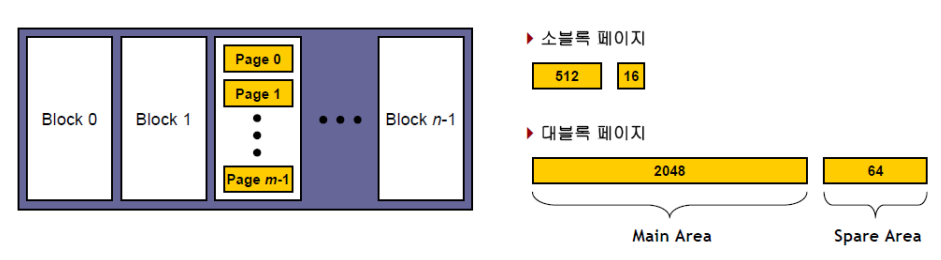
NAND Flash Memory 구조
- 각 칩은 N개의 Block으로 구성
- 각 블록은 m개의 page로 구성
- Main Area : 실제 데이터를 저장하는 공간
- Spare Area : 데이터를 관리하기 위한 데이터 (= 메타 데이터) (페이지 넘버, 블록 넘버 등을 저장)
-> 데이터를 효율적으로 관리하기 위하여
1. 소블록 플래시 메모리
2. 대블록 플래시 메모리
-> 2개로 분류가 된다 (4배 차이)
Flash Memory vs Hard Disk
(중요!!)
1. seek/rotation time이 없음
- 하드 디스크는 Mechanical vs Flash Memory는 Electrical
- Flash Memory 상에서 random access 시 I/O cost 거의 동일
2. 읽기/쓰기가 동일하지 않음
- write cost가 read보다 10배 비쌈
3. in-place update가 없음 (같은 자리 업데이트가 안된다)
- 쓰기전에 지움
- 별도의 erase operation이 필요 (erase cost는 write보다 10배 정도 비쌈)
- In-place update를 하기 위해서는 매우 큰 비용이 요구
----------------------------------------------------------------------------
in-place란?
같은 위치에 저장을 시키는 것
out-of place란?
다른 위치에 저장시켜놓고 그 위치로 찾아가게 하는 것
----------------------------------------------------------------------------

Flash Memory의 기본 연산
1. Read page (chip #, block #, page #)
2. Write page (chip #, block #, page #)
3. Erase block (chip #, block #) -> block 단위로 erase
4. Copy-back page (chip #, target block #, target page #, source block #, source page #) -> 참조만

In-place update 의 한계

1. 다른 블록에 페이지에 대한 정보를 write 해놓음
2. write할 블록을 erase
3. 다른 블록에 저장해 놓은 page 정보를 원래 블록에 re-copy해줌
4. 다른 블록에 저장해 놓은 page 정보를 erase
(erase는 큰 비용이 발생)
-> 대부분의 경우는 out-of-place update를 사용 (새로 작성한 정보의 위치 데이터를 관리하는 방식)
Flash Memory S/W 구성
1. Flash File System
- 일반적인 파일 시스템 사용 가능
2. FTL(Flash Translation Layer) -> 주소에 대한 관리
3. Flash Device Driver
- 읽기/쓰기/erase 지원

----------------------------------------------------------------------
1. Dedicated Flash File System
- Flash File System과 FTL을 합친 구조
2. Flash Device Driver

FTL (Flash Translation Layer)
1. File system의 기본적인 역할
(1) 공간 할당 (가상의 공간이 있다고 가정)
ex) cluster단위를 사용한다고 할 때, 1byte를 저장하려고 하면, 1cluster크기의 공간을 할당 (cluster = 512B = 1 sector)
ex) cluster = 2setocr이라면, Flash Memory에서 page 2개(물리적 공간) 에 저장이 된다
- 가상의 cluster의 위치와 실제의 cluster의 위치는 같을 필요가 없음
2. FTL의 역할
(1) File System의 가상의 공간에 있는 데이터를 Flash Memory에 있는 물리적 공간으로 매핑을 해줌


Mapping
1. Sector Mapping
- 섹터 단위로 매핑을 함
쓰기 과정 :
(1) ftl_write( lsn = 9, A); 함수를 호출
(2) FTL의 mapping table에서 lsn, psn 확인
(3) fdd_write( psn=3 , A); 함수를 호출
write(9, A')으로 업데이트 했다면 ? (Flash Memory는 in-place update 불가능)
(1) ffl_write( lsn = 9, A'); 함수를 호출
(2) FTL은 다른 비어있는 sector(13, 14, 15 등) 하나를 할당해줌 -> 13에 할당했다고 가정
-> lsn=9인 mapping table의 psn이 3에서 13으로 바뀌어야 함
(3) A를 작성한 위치인 psn=3 위치를 Garbage List (링크드 리스트로 관리)에 넣어줌
(4) fdd_write( psn=13, A'); 함수를 호출
더 이상 할당할 공간이 없을 경우
(1) Garbage List에 있는 인덱스 하나를 꺼내옴
(2) 그 인덱스를 갖는 Block이 비어있는 지를 확인
- 비어있지 않는다면 그 Block에 있는 데이터를 빈 Block으로 이동 후 erase
(비어있는 Block이 무조건 1개 이상 있어야 함)
(3) 이동된 Block 중에서 비어있는 공간에 데이터를 저장함
읽기 과정 :
(1) ftl_read( lsn = 9, buf); 함수를 호출
(2) FTL의 mapping table에서 lsn, psn 확인
(3) fdd_read( psn=3 , buf); 함수를 호출
ftl_read의 buf 크기(sector) 단위
fdd_read의 buf 크기(page) 단위
-> buf의 크기가 다름
아래 그림에서 사용할 수 있는 Block의 수는 3개, sector는 12개임

단점 : page의 수가 많아질수록 Address mapping table의 크기가 그만큼 커지게 됌.
(FTL은 RAM에 저장)
2. Block Mapping
- 블록 단위로 매핑을 함
쓰기 과정 : (1 block = 4 sectors 의 경우)
(1) ftl_write( lsn = 9, A) 를 한다면 lbn = lsn/4 = 9/4 = 2 (몫)
(2) offset = lsn mod 4 = 1 (나머지) 위치에 저장 (1번 블록에 저장하고 같은 위치(1번 페이지)에 저장)
(3) fdd_write( ppn = 5, buf ) (buf = (512 + 16)B = 페이지 크기만큼)

읽기 과정 :
(1) ftl_read( lsn = 9, buf ) (buf = 512B) 임
(2) 쓰기 과정처럼 lbn, offset을 계산하여 어디에 저장되어 있는지를 check
(3) fdd_read( ppn = 5, buf ) (buf = (512 + 16)B = 페이지 크기만큼)
ex) ppn = 1 *4 + 1 = 5
업데이트 과정 :
(1) 처음 작성하는 것인지 아닌지를 check (lbn에 매칭되는 pbn의 값이 -1이면 처음 작성하는 것)
(2) 쓰기를 하려는 위치에 데이터가 작성되어 있는지 아닌지를 check
=> update를 해야하는 상황인지 확인 가능
(3) 쓰기를 하려는 위치(a) 에 데이터가 작성되어 있으면
-> 다른 빈 블록의 같은 페이지 위치에 write해주고 (a)에 작성되어있는 나머지 데이터를 copy
-> (a) 블록을 erase
- 빈 블록은 항상 1개 이상 필요함 !!
단점 : update가 많이 발생하는 상황에서는 비효율적 (update가 발생하는 과정에서 많은 비용이 발생)
공간 낭비가 있음 (데이터가 저장되어있지 않은 페이지가 존재함)
3. Hybrid Mapping
Write 과정
ftl_write( lsn = 10, A)
( lsn = 11, B)
( lsn = 9, C)
( lsn = 8, D)
| A | 10 |
| B | 11 |
| C | 9 |
| D | 8 |
-> 비어있는 첫 번째 페이지에 순차적으로 데이터를 저장하는 방식
( 하지만 C, D를 작성하지 않는다고 하면 또 낭비되는 공간이 존재함 )
Update 과정
1. ftl_write( lsn = 10, A)
( lsn = 11, B)
( lsn = 10, A' )
( lsn = 10, A'' )
| A | 10 |
| B | 11 |
| A' | 10 |
| A'' | 10 |
(Block 1)
=> update하는 비용이 줄어듦 (copy를 할 필요가 없어짐)
위의 표에서 새로운 Column 하나를 추가 ( 마지막에 저장된 위치의 offset 정보 추가 )
2. ftl_write(lsn = 8, c)
| A'' | 10 |
| B | 11 |
| C | 8 |
(Block 3)
3. fdd_write(ppn = 3*4 + 2, c 8)
= fdd_write(ppn = 14, c 8)

-> offset이 필요없음
-> spare 영역에 logic sector number(lsn) 을 꼭 작성해줘야 함
(순차적으로 작성하는 것이어서 어디에 위치해있는지를 확인하기 위해서)
Read 과정
ftl_read( lsn = 11, buf)
-> scan을 할 때, 아래서 위로 확인 (최신 데이터는 아래에 존재하기 때문에)
(spare값을 확인해서 read하려는 lsn 과 같은지 확인)
-> Block Mapping 에 비해 Read할 때, 비용이 많이 발생
(Block Mapping은 offset을 통해서 바로 위치를 알 수 있지만, Hybrid Mapping은 최악의 경우에 블록에 있는 모든 페이지를 다 읽어야 할 수도 있음)
Wear-Leveling
- 블록의 소거(erase) 횟수가 제한 (100,000회까지 허용)
- 블록의 소거 횟수가 균등하도록 관리
- 브록의 소거 횟수(Erase Count : EX)가 낮은 순으로 빈 블록 할당
'파일처리' 카테고리의 다른 글
| 파처 ch5) Managing Files of Records (0) | 2025.04.15 |
|---|---|
| 파처 ch4) Fundamental File Structure Concepts (0) | 2025.04.10 |
| 파일처리 ch3) 보조 저장장치와 시스템 소프트웨어 (1) | 2025.03.23 |
| 파일처리 ch2) 파일처리 기본 연산에 대한 소개 (0) | 2025.03.23 |
| 파일처리 ch1) 파일 구조 설계와 명세 소개 (1) | 2025.03.23 |