simple Linear Regression
기본 형태 :

- From training data, learn model coefficients : β0^, β1^
- predict y on the bases of x :


Residual sum of squares (RSS)
- 예측값과 실제값 사이의 차이를 제곱해서 모두 더한 값

- RSS가 작을수록 모델이 데이터를 더 잘 설명하고 있다는 뜻
- RSS가 크면 예측이 실제 데이터와 많이 다르다는 뜻
- RSS는 선형회귀에서 최적의 선형모델을 찾기 위한 기준으로 자주 사용
How accurate is our model?

예시)

Standard error (SE) - 표준 오차
- 추정값이 반복 샘플링(repeated sampling) 상황에서 얼마나 변할 수 있는지를 나타내는 지표
(즉, 같은 모델을 여러 번 반복해서 만들었을 때 계수의 추정치들이 얼마나 흔들릴지를 알려줌)

1. 표본 개수 n이 커질수록 -> SE는 작아짐 (많은 데이터를 쓰면 추정이 더 안정적임)
2. xi들이 평균에서 멀리 퍼져 있을수록 -> SE는 작아짐 (다양한 입력값이 있을수록 기울기 추정이 정확해짐)
Confidence interval (신뢰구간)

β0, β1 이 위에 있는 사진의 신뢰 구간 안에 포함되어 있을 확률이 95% 임

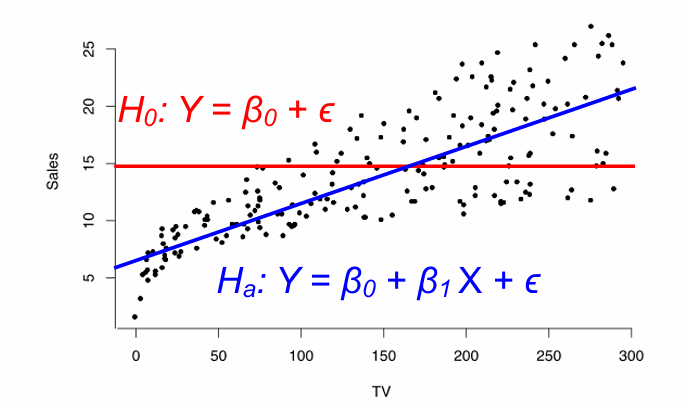
Hypothesis test

β1 = 0 이면 H0이 성립한다 (즉, X와 Y 사이에 관계가 없음)
The t-statistic
- The null hypothesis is tested by a t-statistic

1. n ≥ 30일 경우 정규분포(normal distribution) 근사 가능
2. p-value : |t| 이상이 나올 확률 -> 작을수록 유의미 => X와 Y 사이에 관계가 있음
(p-value < 0.05이면 H0을 기각시킴)

Assessing the accuracy of the model (모델 성능 평가 지표)
Residual Standard Error (RSE) - 잔차 표준 오차

-> 데이터의 오차(e)의 표준편차에 대한 추정치
R² Statistic : 설명된 분산 비율 (fraction of variance explained using X)

- TSS : 전체 변동 (Total Sum of Squares)
- RSS : 설명하지 못한 부분 (left unexplained after regression)
- R² 은 0~1사이 -> 1에 가까울수록 설명력이 높음
'머신러닝' 카테고리의 다른 글
| 머신 러닝 ch5) Multiple Linear Regression (0) | 2025.03.26 |
|---|---|
| 머신 러닝 ch3) 모델 정확도 평가 (Assessing Model Accuracy) (1) | 2025.03.25 |
| 머신 러닝 ch2) 통계적 학습이란(Statistical Learning) ? (0) | 2025.03.25 |
| 머신 러닝 ch1) 통계적 학습 개요 (2) | 2025.03.25 |