Marvin Minsky (마빈 민스키)
- 유명한 인지 컴퓨터 과학자, 철학자
- John McCarthy (존 매카시) 와 함께 MIT AI 연구실의 공동 창립자
Aritificial intelligence (AI)
- 목적 : 인간처럼 생각하고 행동할 수 있는 기계를 만드는 것
- AI = computational rationality (합리적 판단)
- 평가 지표 : 인간 수준의 성능
Turing test

- 인간 질문자가 질문을 하고 인간과 컴퓨터가 그 질문에 대한 응답을 해줌
-> 어떤 것이 인간 답변이고 어떤 것이 컴퓨터 질문인지 판단하는 test
AI, Machine Learning, and Deep Learning
- AI ⊃ ML ⊃ DL
Machine learning
- 머신러닝 = 데이터로부터 학습하는 것 (learning from data)
- 흔한 유형들
1. Supervised (지도)
2. Unsupervised
3. Reinforcement (강화)
4. self-supervised
Learning from data
-> 논리적인 해결책이 없을 때
-> 그러나 경험적인 해결책으로 만들어진 데이터가 있을 때 사용
ex) '데이터' 로부터 나무가 있는지 없는지에 올바른 답변을 함
but 나무의 정의를 물어보면 결론이 나지않는 답변을 함
The essense of learning from data
중요!!!
1. 데이터를 가지고 있다
2. 그 안에 패턴이 존재한다
3. 우리가 수학적으로 그것을 정확히 알 수 없다
1. 학습보다는 규칙 기반으로 해결 가능 (소수 판별 알고리즘 존재)
- 규칙이 명확해서 학습 불필요
2. 거래 패턴이 복잡하고, 명확한 규칙으로 분류하기 어려움 (학습이 매우 유용한 분야)
3. 물리 법칙(운동 방정식)으로 정확하게 계산 가능
4. 환경 변화가 많고, 명확한 해법이 어려움
- 학습 기반 최적화(강화학습 등)이 매우 유용
Learning paradigms (학습 패러다임)
1. 데이터로부터 학습하는 기본 전제
- 관찰을 통해 기본 프로세스를 밝혀냄
- 단일 프레임워크에 맞추기에 매우 광범위하고 어려움
2. 기본 학습 패러다임
(1) Learning from data (데이터로부터 학습)
- supervised learning
- unsupervised learning
(2) Learn by interaction (상호작용을 통해 학습)
- reinforcement learning
(3) notable learning methods in active research (활발한 연구에서 주목할 만한 학습 방법) - 딥러닝!!
- representation learning (ex: 딥 러닝)
- self-supervised learning : pretext task -> downstream tasks
- transfer learning and domain adaptation (전이 학습 및 도메인 적응)
- continual learning, multi-task learning, few-shot/zero-shot learning
Supervised learning
- 가장 많이 연구되고 가장 많이 활용되는 학습 유형
- 지도 학습 설정
- > 훈련 데이터에는 주어진 input에 올바른 output이 무엇인지에 대한 명확한 예가 포함
- learning is 'supervised'
1. 어떤 'supervisor' 가 각 입력 데이터에 대해 정답(출력값)을 지정해줬다
2. 훈련 데이터의 각 샘플마다 정답(라벨) 이 존재
* label (라벨)
1. integer - ex) 0, 1, 2, 3
2. sparse - ex) [1, 0, 0], [0, 1, 0], [0, 0, 1]
- most 잘 알려진 접근법 : classification(discreate) & regression(continuous)
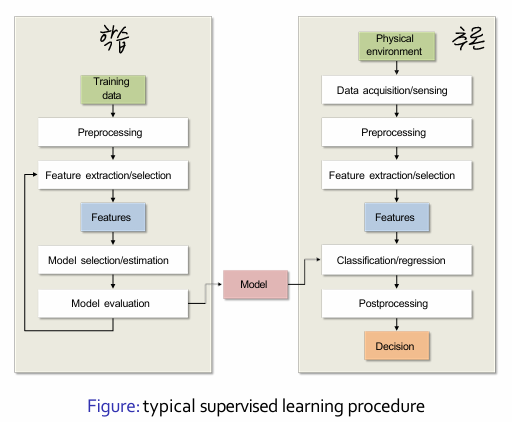
학습 : 훈련 데이터 -> 전처리 -> 특징 추출/선택 -> 특징 -> 모델 선택/추정 -> 모델 평가
추론 : 물리적 환경 -> 데이터 수집/감지 -> 전처리 -> 특징 추출/선택-> 특징 -> 분류/회귀 -> 후처리 -> 결정
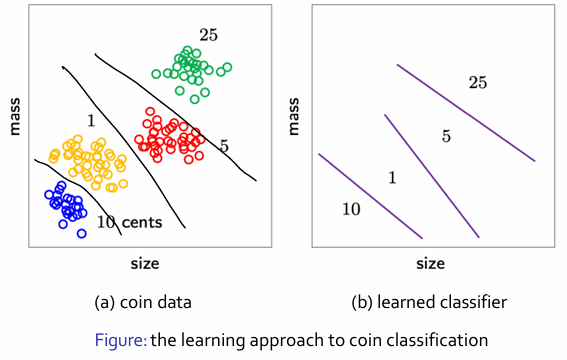
- 분류 => 기준 => decision boundary (결정 기준선)
- feature : 구별 분포 정보
Reinforcement learning
- training data가 각각의 input에 올바른 output을 포함하고 있지 않는다면
-> 더이상 supervised learning setting이 아님
ex) 뜨거운 차를 만지지 않도록 배우는 유아
-> training examples은 무엇을 해야하는지 알려주지 않음
->그럼에도 불구하고, 그녀는 더 나은 행동을 강화하기 위해 예를 사용
-> 결국 그녀는 비슷한 상황에서 무엇을 해야하는지를 배움
Learning != memorization
- 이는 강화 학습의 특징
1. training dxample은 target output을 포함하고 있지 않음
-> 즉, 무엇이 '정답'인지 알려주지 않음
2. 대신, 어떤 행동(output)을 취했을 때 그 결과가 얼마나 좋은지(reward) 에 대한 정보만 제공됨
-> ex) 게임에서 점수, 로봇의 이동 거리, 추천 시스템의 클릭률 등
- 강화 학습은 게임 학습에 유용하게 사용됌 (Game Agent)
- 다른 많은 작업에도 적용 가능 -> ex) ChatGPT : 인간의 피드백을 통한 강화 학습 (RLHF)
*RLHF : 사람처럼 말하는 느낌
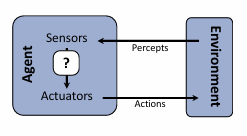
Designing rational agents
1. Agent란?
- 감지(perceive)하고 행동(act)하는 존재
- 현실 예시 : 로봇, AI 플레이어, 자율주행차, 마케팅 시스템 등
2. Rational Agent란?
- 자신의 기대 효용(utility)을 최대화하는 방향으로 행동을 선택함
- 즉, 현재 상황에서 가장 이득이 되는 행동을 하려고 노력하는 AI
3. 행동 선택의 기준
- percepts (지각 정보) : 환경으로부터 받은 관측값
- environment (환경) : 에이전트가 작동하는 세계
- action space (행동 공간) : 에이전트가 선택할 수 있는 가능한 행동들
Unsupervised learning
1. training data는 output information이 전혀 포함되어 있지 않음
-> 단지 input만 가지고 있음
2. 비지도 학습에 대한 접근 방식
- clustering (군집화)
ex) k-means, mixture models(혼합 모델), hierarchical(계층적)
- density estimation (밀도 추정)
- feature extraction (특징 추출)
ex) PCA, ICA, SVD
3. variants (변형)
- semi-supervised learning, self-supervised learning
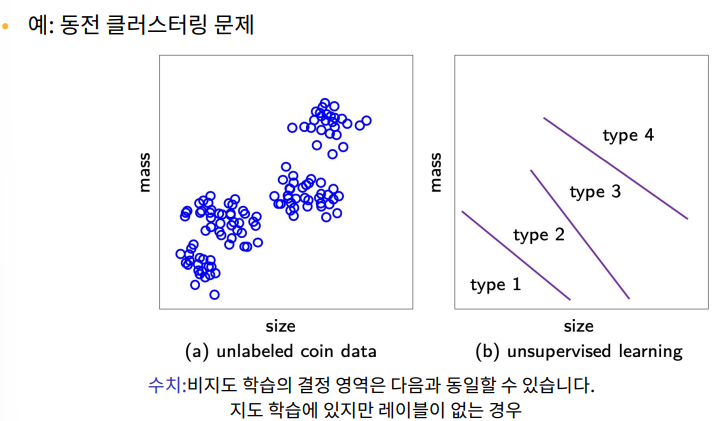
비지도 학습은 ?
1. input data에서 자발적으로 패턴과 구조를 발견하는 것
-> 정답(레이블)이 없는 상태에서 데이터 내부의 규칙성이나 군집을 발견
ex) 책 세트를 주제별로 분류
2. 지도 학습의 선구자 (지도학습의 전 단계로 활용될 수 있음)
ex) 의미를 먼저 모른 채 스페인어를 배우고 나서 스페인어 수업을 듣는 것이 더 쉬움
즉, 비지도학습을 통해 데이터 구조를 먼저 파악하면, 지도학습 성능 향상에 도움이 됌
3. 데이터를 더 높은 수준의 표현으로 추상화하는 방법
-> 복잡한 원시 데이터를 간결하게 요약 또는 특징 추출
ex) 자동 특성 추출(automated feature extraction), 차원 축소(PCA)

i) 동전의 크기, 무게, 액면가 정보를 미국 조폐국(U.S. Mint)으로부터 받아와서 분류에 활용
-> 사람이 미리 정해준 규칙을 따르는 것 = 학습 없음
-> 직접적인 학습(데이터로부터 규칙 학습) 없이 룰 기반 시스템(rule-based system) 임
ii) 알고리즘이 라벨이 붙은 동전 데이터를 바탕으로 경계(boundary)를 학습해 분류
-> 명확한 입력-출력 쌍 (동전 특성 -> 액면가 라벨)
-> 이는 지도학습
iii) 컴퓨터가 틱택토 게임을 하며 스스로 전략을 조정, 지는 행동을 줄이도록 학습
-> 시행착오(trial & error)를 통해 보상 기반 학습
-> 전형적인 강화학습

'문제해결(머신러닝)' 카테고리의 다른 글
| 문해 ch2) Feasibility of Learning (학습의 실현 가능성) (1) | 2025.03.26 |
|---|